ElasticSearch is the premier second generation NoSQL datastore. It took all the lessons learned from building BigTable and Dynamo style datastores and applied them to creating something that hadn't really existed yet: a datastore that lets you slice and dice your data across any dimension.
At Klout, I've been tasked with a few projects that sounded technically challenging on paper. ElasticSearch has made these laughably easy. Like a couple hours of off and on hacking while sipping a bloody mary easy.
Fuck "bonsai cool." ElasticSearch is sexy. Ryan Gosling with a calculator watch sexy.

Unfortunately...
Unfortunately, there is one feature that ElasticSearch is missing. There is no multi-dimensional routing.
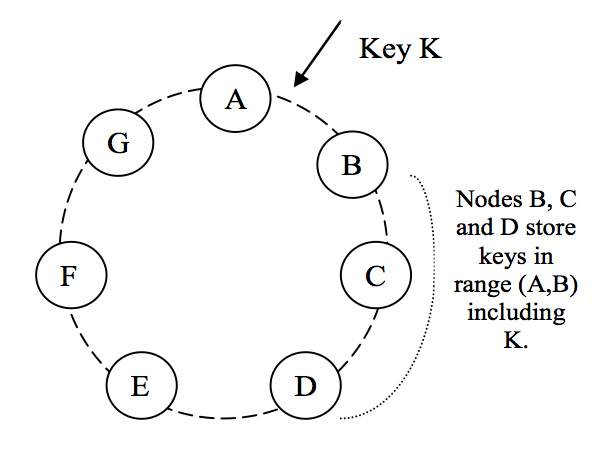
Every NoSQL datastore does some type of sharding (not to be confused with sharting.) Riak has vnodes, HBase has regions, etc. This partitions your data horizontally so that each node in your cluster owns some segment of your data. Which shard a particular document goes to is usually determined by a hashing function on the document id.
In ElasticSearch, you can also specify a routing value, which allows you to control which shard a document goes to. This helps promote data locality. For example, suppose you have an index of notifications. Well, you can route these feed items by the user id of the notification instead of the notification id itself. That means when a user comes to the site and wants to search through the notifications, you can search on just one shard instead of the entire index. One box is active instead of dozens. This is great since you never really search across users for notifications anyways.
Taking this one dimension further, suppose I have advertising impression data that has a media id (the id of the ad shown,) a website id (the id of the website the ad was shown on,) and a timestamp. I want to find distribution of websites that a particular media id was shown on within a date range. Okay, so let's route by media id. No big deal. Two weeks later, product wants to find the distribution of media shown on a particular website. Well fuck. Nothing to do now except search across the entire index, which it so expensive that it brings down the entire cluster and kills thousands of kittens. This is all your fault, Shay.
What would be ideal is a way to route across both dimensions. As opposed to single dimensional routing, where you search a particular shard, here you would search across a slice of shards. Observe...
Tokamak
If we model a keyspace as a ring, a two dimensional keyspace would be a torus. Give it a bit of thought here. You create a ring by wrapping a line segment so that the ends touch. Extruding that to two dimensions, you take a sheet of paper and wrap one end to make a cylinder and then the other end to make the torus.
A shard here would be a slice on the surface of the torus (we are modeling it as a manifold instead of an actual solid.) Now when we search by media id, we're going across the torus in one direction, and when we search by website id, we're going across the torus in the other direction. Simple, right? I don't think this even needs to be a new datastore. It could just be a fork of ElasticSearch with just this feature.
There a few implications to increasing the number of dimensions we can route on. You are restricted to shard numbers of xn shards where n is the number of dimensions. You also really have to plan out your data before hand. ElasticSearch is a datastore that encourages you to plan your writes so that you don't have to plan your reads. Tokamak would force you to establish your whole schema beforehand since the sharding of your index depends on it.
In terms of applications, advertising data is the most obvious. That industry not only drives 99% of datastore development, but also employs 99% of all DBAs to run their shit-show MySQL and Oracle clusters.
Well, hope you enjoyed this post, just like I also hope to find the time to work on this, in between writing my second rap album and learning Turkish. If only I could convince someone to pay me money to program computers.